Oricum, mi-am amintit că, atunci când am citit "Optimizing Oracle Performance" era o schemă în care se prezenta cum un proces este alocat/dealocat de pe procesor de către sistemul de operare. Cary Millsap, autorul cărții, preciza că respectiva figură e din "The Design of the Unix Operating System", scrisă de Maurice Bach.
Îmi zic: "păi dacă Cary Millsap face referire la cartea asta, trebuie să fie o carte bună, nu-i așa?". Ia să vedem ce-i cu ea! Dau o căutare pe Google și, surpriza! Cartea e apărută prin 1986. Asta-i prea de tot, îmi zic. Totuși, Cary Millsap a publicat cartea mai sus amintită în 2003, deci la vreo 17 ani după... Prin urmare, îmi asum riscul și mă hotărăsc să mi-o cumpăr, gândindu-mă, aproape cu jenă, că îmi faceam probleme înainte de a da banii pe cartea D-lui Prof. Fotache, pentru că, vezi Doamne, ar fi apărut în 2009 și deja, în trei ani, informația ar putea fi perimată.
Așa se face că m-am "procopsit" cu această bunicuță a cărților din domeniul IT (oare să-i spunem letopiseț?) și am început lectura, recunosc cu o oarecare suspiciune, gândindu-mă că poate lucrurile descrise acolo nu mai sunt valabile demult. Așa că, din când în când îl mai intrebam și pe maestru nostru "sysadmin": "colegu', e adevărat ce se spune aici?". De cele mai multe ori primeam confirmarea, așa că, prima concluzie e că, de fapt, arhitectura acestor sisteme a rămas la bază aceeași.
Dar, mai bine, haideți să vă spun, în mare, cam despre ce este vorba în această carte. În articolul de azi am să vă povestesc doar despre primul capitol și al doilea, pentru a evita un articol luuung, cât o zi de post. Am făcut deja greșela asta la o parte din articolele de pe acest blog și nu cred că cititorul a fost prea încântat. Oricum, promit să revin cu lucruri interesante și din următoarele capitole.
Capitolul 1: GENERAL OVERVIEW OF THE SYSTEM
 |
| Figura 1 - Calculatorul GE-645 |
Părinții sistemului UNIX sunt: Ken Thompson și Dennis Ritchie. Pe paginile Wiki există și o poză cu cei doi împreună (vă rog, nu vă gândiți care-i mama și care-i tata). Ambii aduc, de departe, cu sysadmin-ul de la noi, așa că, stau și mă gândesc că poate barba, eventual și pletele, sunt un accesoriu important în comunitatea UNIX-iștilor.
Apoi, ni se prezintă o primă structură a sistemului de operare, așa, ca din avion. De la această înălțime avem "hardware"-ul, cu care interacționează "kernel"-ul și peste, aplicațiile obișnuite care, prin acele "sys-call"-uri, invocă diferite servicii oferite de "kernel".
Mai departe, este descris sistemul de fișiere, cu modelul său de permisiuni, dar și o scurtă introducere în felul în care sistemele UNIX realizează managementul proceselor: fork, exec, exit etc. Acestea sunt noțiuni cunoscute și nu sunt aprofundate sub nici o formă în acest capitol.
Spre sfârșitul capitolului, avem parte și de câteva detalii, ceva mai interesante. Astfel, reținem că există două moduri în care un proces poate să ruleze: modul utilizator (user mode) și modul kernel. În modul utilizator, procesul nu poate accesa decât propriile instrucțiuni și date, neputând atinge nimic legat de "kernel", lucru posibil totuși în modul "kernel".
 |
| Figura 2 - Ierarhia întreruperilor |
Există chiar și un fel de ierarhie a acestor întreruperi, ordonate după priorități. "Kernel"-ul poate decide să ridice nivelul de la care procesorul să poată fi întrerupt. Spre exemplu, dacă nivelul de întrerupere este stabilit la cel asociat discului, atunci nici un alt dispozitiv în-afara ceasului sistem nu mai poate întrerupe procesorul. Acest aspect este important, mai ales în contextul anumitor algoritmi interni ai kernelului, unde o întrerupere într-un anumit punct al logicii lor, ar putea crea probleme (spre exemplu, actualizarea listelor dublu înlănțuite).
Primul capitol nu se putea încheia fără a se spune ceva și despre managementul memoriei. Se punctează că, fiecare proces operează cu adrese de memorie virtuale, iar "kernel"-ul împreună cu hardware-ul lucrează îndeaproape pentru a translata adresele virtuale în adrese fizice. Practic, fiecare proces are impresia că doar el există în sistem și are la dispoziție toată memoria fizică.
Capitolul 2: INTRODUCTION TO THE KERNEL
Dacă în primul capitol am avut parte de o descriere generală a sistemului UNIX, următorul capitol se concentrează strict pe partea de "kernel" și își propune introducerea acelor noțiuni fără de care înțelegerea în profunzime a sistemului UNIX nu ar fi posibilă. |
| Figura 3 - Arhitectura UNIX |
De jos în sus, observăm mai întâi interacțiunea kernel-ului cu hardware-ul. Nu ne interesează detaliile privind această interacțiune. Ne așteptăm să fie la un nivel cod mașină, bițișori, asamblare etc. Cert e că, în final, prin această interacțiune, cutia aia cu beculețe, firișoare și alte ciudățenii, numită calculator, prinde viață.
Mai departe, cu acest nivel de abstractizare, denumit în figură "hardware control", putem construi independent de platformă două mari componente ale sistemului:
- sistemul de fișiere
- sistemul de management al proceselor
Dacă ar fi să contextualizăm discuția, ne amintim că în Oracle, o problemă destul de serioasă era atunci când "buffer cache"-ul din sistemul de operare intra în conflict cu "buffer cache"-ul din Oracle. Practic, două strategii de "buffering" se "ciocăneau", dat fiind că nici una nu știa de cealaltă. Soluția era să ocolim "buffer cache"-ul sistemului de operare și să accesăm fișierele bazei de date, fie în maniera "raw", fie instruind serverul să folosească opțiunea O_DIRECT la deschiderea fișierelor de date.
Pe măsură ce scriu, îmi dau seama tot mai mult că acest articol recurge din ce în ce mai des la romgleza atât de dragă nouă IT-iștilor, dar zău că nu știu cum să traduc "buffer cache", "raw" și altele. Asta e, am să mă aștept și la comentarii răutăcioase.
Dreptunghiul acela mare din figură denumit "file subsystem" cred că nu mai are nevoie de alte precizări. E vorba de sistemul de fișire și directoare cu care suntem deja familiarizați.
Cea de-a doua mare componentă este dată de cea responsabilă cu managementul proceselor: alocarea/dealocarea proceselor pe CPU (scheduler), bucătăria internă legată de memorie (memory management) și comunicația inter-procese.
Toate serviciile oferite de kernel sunt frumos împachetate și oferite "publicului larg" sub forma unui API de funcții sistem pe care aplicațiile le pot apela după bunul plac.
Mai multe despre sistemul de fișiere
În spatele fiecărui fișier se găsește un descriptor denumit "inode". Acesta conține metadate privind fișierul cu pricina:- utilizatorul și grupul cărora fișierul aparține
- drepturile asociate
- informații privind data creării, când a fost accesat ultima data etc.
- date cu privire la blocurile efective unde conținutul fișierului se găsește
- alte meta-date
Buuun, deci reținem conceptul de "inode" ca fiind foarte important pentru a înțelege interacțiunea la nivelul sistemului de fișiere. Deși, în general, aplicațiile noastre lucrează cu căi și denumiri de fișiere, în spate, acestea sunt convertite în "inode"-uri.
Mai departe, se introduc trei noi structuri, de asemenea foarte importante în contextul lucrului cu fișiere. Este vorba despre tabela cu fișierele deschise la nivel de proces, tabela globală cu toate fișierele deschise în sistem și tabela cu "inode"-uri. Relațiile între cele trei tipuri de tabele sunt prezentate în "Figura 4".
 |
| Figura 4 - Relațiile între tabele de fișiere |
Mi-a plăcut faptul că autorul nu uită să explice și relația sistemelor de fișiere cu dispozitivele fizice (în special discul). Astfel, "kernel"-ul nu operează direct cu discuri fizice, ci, mai degrabă, cu dispozitive logice. Ori de câte ori se crează o partiție expunem, în fapt, un așa-numit "logical device", care, între noi fie vorba, din punctul de vedere al "kernel"-ului e un identificator numeric. Conversia acestui identificator într-o adresă fizică va fi realizată de către "driver"-ul dispozitivului. Fiecare partiție poate avea sistemul ei de fișiere, care, în mare, arată ca în "Figura 5".
 |
| Figura 5 - Structura sistemului de fișiere |
Despre procese
Există pe la începutul capitolului un citat a lui Christian K., din lucrarea "The UNIX Operation System", în care se spune că "UNIX-ul dă iluzia că în sistemul de fișiere găsim locațiile, iar procesele au viață" (oare nu e la fel prin toate sistemele de operare?). Această a doua parte a capitolului doi se referă la partea "vie" a sistemului.În primul rând trebuie elucidat ce-i ăla un proces. Un proces apare ca urmare a execuției unui program (cod) și conține trei părți principale: text (adică partea de instrucțiuni), date (adică zona alocată pentru stocarea variabilelor/constantelor globale din program) și stivă, care reprezintă o structură alocată dinamic de către kernel, în care se stochează valoarea argumentelor sau a anumitor variabile din context de la un apel de metodă la altul.
Toate procesele din sistem, cu excepția așa-numitului "proces 0" care este creat într-o manieră specială de către kernel în momentul inițializării, sunt create prin invocarea unei funcții sistem denumite "fork" care, printre altele, alocă procesului nou creat și un identificator unic, regăsit prin documentație ca PID (Process ID). Este important de menționat că fiecare proces rulează în izolare, în sensul că nu poate accesa sau modifica zone de memorie aparținând altor procese. Este adevărat că anumite zone de memorie, în special cele asociate cu instrucțiunile proceselor (zona "text"), pot fi partajate între procese (în modul citire), dar acest lucru se realizează transparent de către kernel, iar procesul în sine nu are habar de acest lucru.
Analog tabelei globale cu toate fișierele deschise în sistem, "kernel"-ul gestionează o așa-numită "tabelă a proceselor" în care vom regăsi câte o intrare pentru fiecare proces din sistem. Această tabelă este folosită de către "kernel" pentru a realiza, global, managementul proceselor. Totuși, există anumite informații care nu trebuie să fie vizibile decât atunci când procesul rulează efectiv. Acestea sunt reunite într-o structură separată denumită "zona U" (în engleză "U area"). Dacă denumirea vă duce cu gândul la "Area 51", ei bine, sunteți pe-aproape. E cam la fel de obscură și necunoscută pentru noi, muritorii de rând. Ea este menționată în acestă secțiune, introductivă de altfel, deoarece va apărea destul de des în descrierea arhitecturii de detaliu a proceselor, așa cum vom vedea în capitolele următoare. Anticipând puțin lucrurile, în această zonă găsim:
- adresa înregistrării părinte din "tabela globală a proceselor" (de fapt e o relație de unu-la-unu)
- dacă procesul invocă o funcție sistem aici sunt stocate argumentele, valoarea returnată, eventual codul de eroare
- directorul curent din care a fost lansat procesul
- tabela cu descriptorii fișierelor deschise, la nivel de proces
- alte nebunii
Ajungem în sfârșit la secțiunea legată de "context switch"-uri. În primul rând trebuie definit contextul. Găsim următoarea descriere: contextul unui proces este dat de starea sa la un moment dat, asa cum este ea definită de către conținutul zonei de date a procesului (valorile curente ale variabilelor globale), a stivei, a înregistrării corespunzătoare din tabela globală de procese, dar și a zonei U, precum și valorile curente din regiștrii-procesor utilizați la acel moment de către procesului în cauză. Atunci când "kernel"-ul decide să scoată procesul curent de pe procesor și să aloce unul nou, discutăm de un "context switch". Adică, înainte de dealocare, "kernel"-ul salvează context-ul procesului astfel încât să îl poată restaura atunci când va decide să realoce procesul cu pricina. O salvare de context are loc și atunci când se invocă o funcție sistem. În acel moment asistăm la o trecere din modul utilizator în modul kernel. Totuși, autorul face mențiunea că, în condițiile când la revenirea din modul "kernel" același proces rulează pe procesor, nu avem de-a face cu un "context switch", ci cu o schimbare de mod.
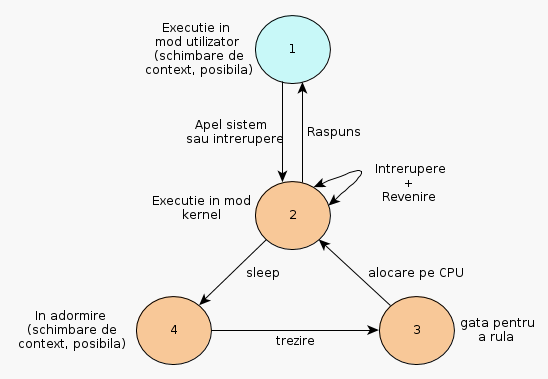 |
| Figura 6 - Ciclul de viață al unui proces |
Un alt aspect interesant pe care l-am găsit citind acest capitol este faptul că, procesele care rulează în modul kernel nu pot fi dealocate de pe procesor. Un "context switch" poate avea loc doar atunci când procesul rulează în modul utilizator sau, conform diagramei, când procesul se află în starea 4, "asleep", adică atunci când doarme. Beneficiul major ține de faptul că, algoritmii implementați în "kernel" se pot baza pe faptul că, pe durata rulării lor, procesul nu va fi dealocat de pe procesor, iar astfel este eliminat riscul de corupere a diferitelor structuri de memorie (globale) utilizate. Pe de altă parte, nu pot să nu mă gândesc că, în fapt, operatia de dealocare și alocare pe procesor se face în modul "kernel", singurul în care este posibil a se realiza acest lucru. Trag concluzia că pe durata unui "system call", procesului i se garantează accesul la CPU, de unde rezultă că, dezvoltatorii "kernel"-ului ar trebui să acorde o atenție deosebită acestor funcții, astfel încât ele să nu dureze foarte mult și astfel să poată da posibilitatea și altor procese să "pună mâna" pe procesor. Bun, am particularizat, dar probabil că acest lucru se întâmplă nu numai cu "sys-call"-urile, ci și cu alte funcționalități de "kernel" ce țin, mai degrabă, de bucătăria sa internă. Spre exemplu, cum ar fi ca, atunci când "scheduler"-ul a pornit dealocarea unui proces care rula, hop că e la rândul său dealocat (oare de cine?), lâsănd în urmă treaba neterminată? E clar că astfel de scenarii sunt imposibile!
Mai trebuie zăbovit puțin și la modalitatea în care un process intră în starea de "adormire" și cum este el trezit. Conform "Figurii 6", discutăm de tranziția de la starea 2 la starea 4, pe de o parte și de la starea 4 către starea 3, pe de altă parte. Un proces se duce la culcare atunci când, fie așteaptă după un eveniment, fie invoca singurel funcția "sleep". Evenimentele de așteptare pot fi multiple. Spre exemplu, s-a invocat funcția de citire dintr-un fișier și, mai departe, așteptăm dispozitivul, să zicem de tip disc, să ne dea răspunsul, dar în loc să stăm sincron, adică să așteptăm activ acest răspuns, mai bine intrăm în starea "sleep" și așteptăm să fim "notificați", asincron, când datele au ajuns și sunt numai bune a fi preluate. Alt tip de eveniment ar putea fi dat de existența unui "lock". Spre exemplu, procesul vrea să manipuleze un bloc din "buffer cache", dar îl găsește blocat de către un alt proces, prin urmare intră în starea de "sleep" și asteaptă să fie "trezit" când blocul va deveni disponibil, caz în care "kernel"-ul va trece toate procesele care dormeau așteptând eliberarea blocului, în starea "gata pentru a fi executate" (în engleză, "ready to run"), de unde, mai departe, "scheduler"-ul va alege un proces și-l va aloca pe CPU.
Foarte importantă, zic eu, este precizarea conform căreia procesele care sunt în starea "sleep" nu consumă procesor. "Kernel"-ul nu se obosește să verifice, cu o anumită frecvență, să zicem, dacă procesele care dorm ar trebui trezite, ci pur și simplu, atunci când intervine evenimentul după care acele procese așteptau, le trezește la realitate. Din perspectiva Oracle observația este importantă. Evenimente de așteptare gen "db file scattered reads" sau "db file sequential reads", deși se adaugă la "DB time", nu consumă CPU.
Exerciții
1. Fie următoarea secvență de comenzi:grep main a.c b.c c.c > grep.out & wc -l < grep.out & rm grep.out &Simbolul "&" de la sfărsit indică faptul că acea comandă va fi executată asincron (în "background"). De ce comenzile de mai sus nu sunt echivalente cu?
grep main a.c b.c c.c | wc -lRăspuns:
Prima variantă nu sincronizează în nici un fel execuția între procese, prin urmare, rezultatul este imprevizibil, adică depinde de ordinea în care "scheduler"-ul va alocal cele trei procese. A doua varianta, este cea sincornizată, cele două procese comunicând prin acel "pipe".
 2. Fie codul din listingul alăturat. Presupunând că are loc o schimbare de context fix atunci când se ajunge la linia de comentariu și că un alt proces
înlătură un bloc din listă prin intermediul următorului cod:
2. Fie codul din listingul alăturat. Presupunând că are loc o schimbare de context fix atunci când se ajunge la linia de comentariu și că un alt proces
înlătură un bloc din listă prin intermediul următorului cod:
remove(qp)
struct queue *qp;
{
qp->forp->backp = qp->backp;
qp->backp->forp = qp->forp;
qp->forp = qp->backp = NULL;
}
dacă luăm în considerare următoarele cazuri:a) procesul înlătură structura bp din lista înlănțuită;
b) procesul înlătură bp1 din lista înlănțuită;
c) procesul înlătură structura imediat următoare după bp1;
Care este starea listei după ce procesul reușește să execute instrucțiunea de după comentariu?
Răspuns:

a) se înlătura "bp". În acest caz, lista nu va fi compromisă deoarece toate legăturile între "bp" și elementele adiacente lui sunt valide. Practic, legăturile lui "bp1" cu "bp" vor fi trasate, de această dată, către elementul dinaintea lui "bp", element nereprezentat în figură. Apoi, la revenirea în instrucțiunea de după comentariu va fi trasată și legătura de la "bp1" la elementul imediat următor.
b) dacă se înlătură bp1, operația de ștergere decurge fără probleme, chiar dacă legătura lui "bp1" cu elementul imediat următor este invalidă. İn schimb, la revenirea în instrucțiunea de după comentariu, avem o problemă. Elementul "bp1" nu mai există.
c) dacă se elimina ultimul element din figură, avem o problemă chiar în operația de ștergere, pentru că, dacă ne uităm cu atenție la prima instrucțiune din această funcție, vedem că referinta pentru elementul de după cel de șters (nereprezentat în figura), în loc să facă legătura cu "bp1", o va face cu "bp", dat fiind că ultima instrucțiune de după comentariu nu a rulat încă.
Deja simt că mi s-au încins neuronii! Exercițiul reprezintă pretextul perfect pentru a conștientiza mai bine de ce trebuie interzise schimbările de context pe durata execuției acestui tip de algoritm. Nu uitați, lista în cauză este una globală!
3. Ce se întâmplă dacă "kernel"-ul încearcă să trezească toate procesele care așteptau după un eveniment, dar descoperă că, de fapt, nu există nici un astfel de proces la momentul apariției evenimentului?
Răspuns:
Conform "Figurii 6" acest lucru nu ar trebui să fie posibil, dat fiind că există o singură alternativă prin care se poate ieși din această stare și anume "wakeup", adică tranziția de la starea 4 la starea 3. Din ce știu eu, un proces în starea "sleep" nici măcar nu poate fi înlăturat printr-o commandă "kill", prin urmare scenariul descris, după umila mea părere nu poate apărea. Dar, desigur, mă pot înșela! Comentariile sunt bine-venite!
0 commentarii:
Trimiteți un comentariu